


Cross-Region Kubernetes: The Ultimate Guide to Pod Communication
Bridging the Divide: How to Seamlessly Connect Pods Across Geographical Boundaries

As organizations scale their Kubernetes deployments globally, a common challenge emerges: how do you enable efficient and secure pod-to-pod communication between clusters spanning different regions, VPCs, and even cloud providers? Whether you're implementing disaster recovery, reducing latency for global users, or building a hybrid cloud infrastructure, mastering cross-cluster connectivity is essential.
In this comprehensive guide, we'll explore the conceptual foundations of connecting distributed Kubernetes ecosystems, with special focus on AWS EKS implementations across multiple regions.
The Challenge of Cross-Region Kubernetes
Before diving into solutions, let's understand what makes cross-region pod communication challenging:
Network Isolation: Kubernetes clusters in different VPCs or regions are network-isolated by default
Service Discovery: Pods in one cluster can't naturally discover services in another
DNS Resolution: Kubernetes DNS services are cluster-scoped
Security Boundaries: Cross-region traffic must maintain security standards
Latency Considerations: Inter-region communication adds latency
Cost Management: Cross-region data transfer incurs costs
Foundational Networking: Creating the Infrastructure Layer
Before Kubernetes services can communicate across clusters, we need to establish the underlying network connectivity. There are two primary approaches when working with AWS EKS:
Transit Gateway: The Enterprise Hub-and-Spoke Approach
AWS Transit Gateway provides a scalable, managed solution for connecting multiple VPCs and on-premises networks, acting as a network transit hub.
Conceptual Overview:
Think of Transit Gateway as a cloud router that connects all your VPCs. Each EKS cluster resides in a VPC, and Transit Gateways in different regions connect to each other via peering connections. This creates a backbone network that allows pods to communicate across regions.
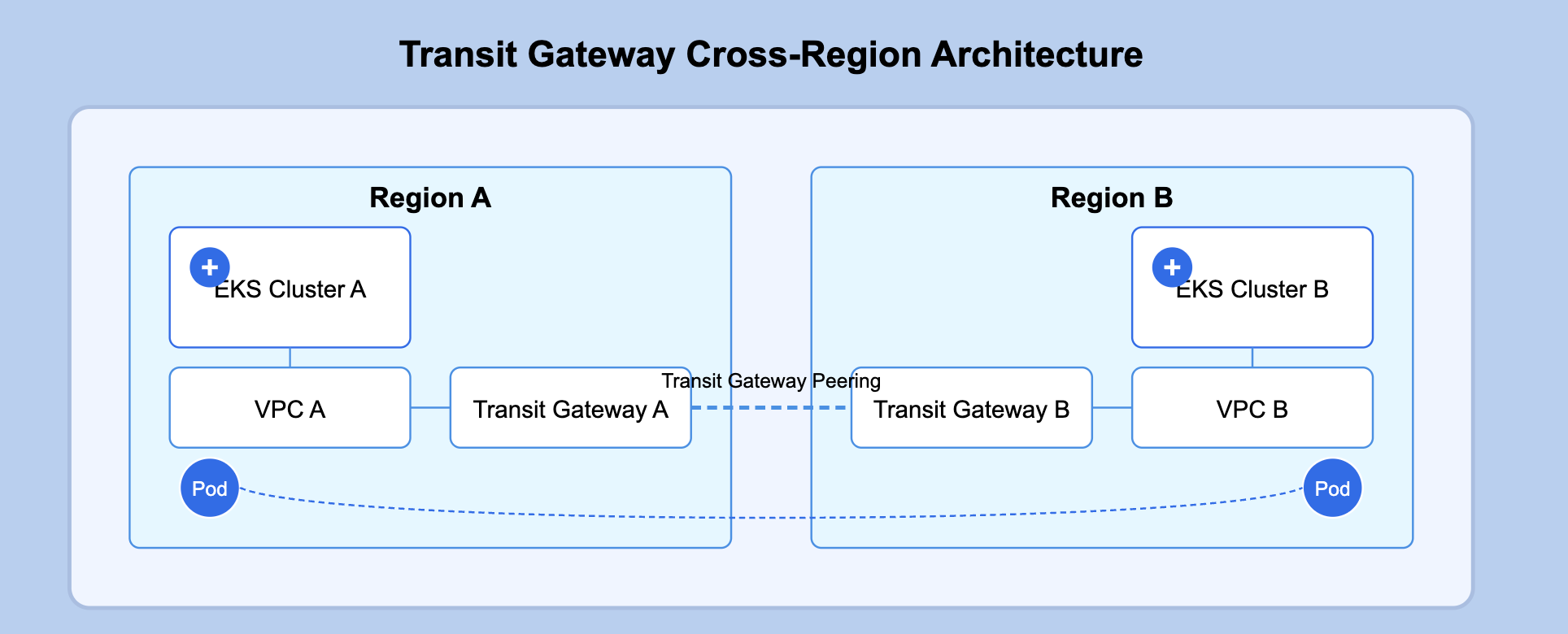
Key Components:
Transit Gateway in each region
Transit Gateway Peering between regions
VPC Attachments connecting each cluster's VPC to its regional Transit Gateway
Route Tables directing traffic between VPCs
Advantages:
Highly scalable for multiple VPCs and regions
Centralized network management
Supports transitive routing (A can talk to C through B)
AWS-managed redundancy and high availability
Disadvantages:
More complex setup
Higher cost than direct VPC peering
Additional hop in the network path
VPC Peering: The Straightforward Approach
VPC Peering provides a simpler alternative for connecting two VPCs directly, establishing a networking connection between them.
Conceptual Overview:
VPC Peering creates a direct highway between two VPCs, allowing resources in either VPC to communicate with each other as if they were in the same network. For EKS clusters, this means pods can directly reach pods or services in the peered VPC using private IP addresses.
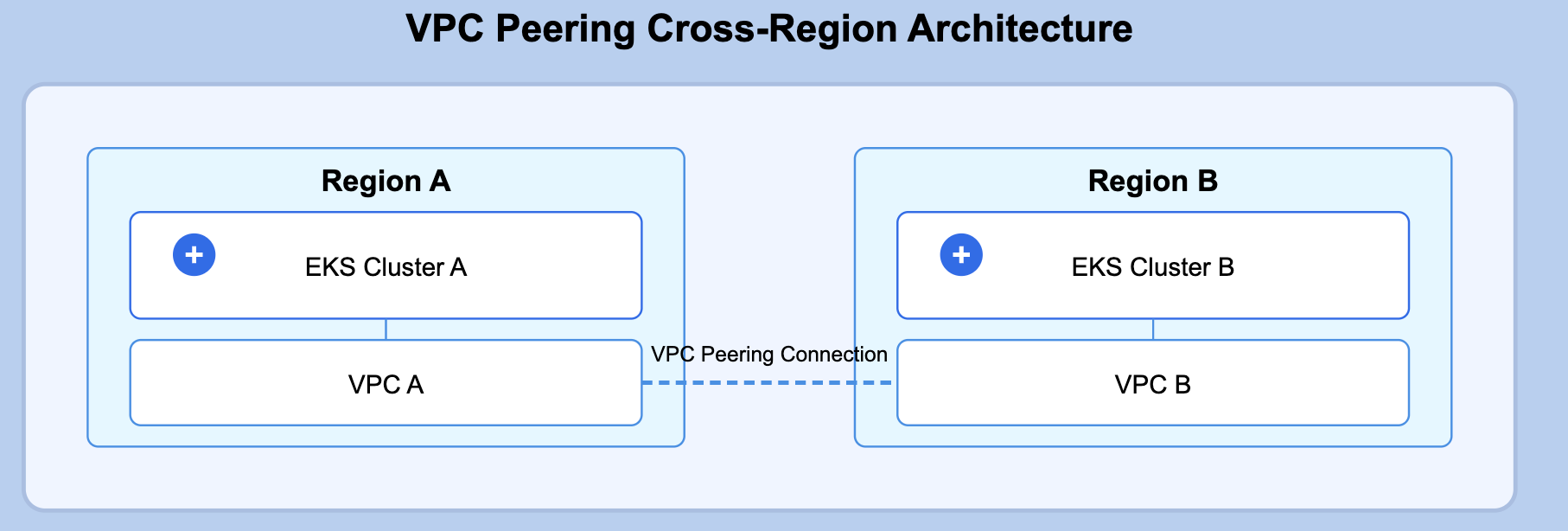
Key Components:
VPC Peering Connection between regional VPCs
Route Tables in each VPC pointing to the peer CIDR blocks
Security Groups allowing traffic between VPCs
Advantages:
Simpler to set up and manage
Direct connection between VPCs
Lower latency than Transit Gateway
No additional cost beyond standard data transfer rates
Disadvantages:
No transitive routing (requires mesh connections for multiple VPCs)
Limited to 125 peering connections per VPC
No centralized management for multiple connections
Service Connectivity: How Pods Actually Communicate
Once the network infrastructure is in place, we need to address how Kubernetes services discover and communicate with each other across clusters.
Basic Pod-to-Pod Communication
With either Transit Gateway or VPC Peering established, pods can technically communicate directly using IP addresses. However, this approach has significant limitations:
IP Address Management: Cluster CIDR ranges must not overlap
No Service Discovery: Requires hardcoding IP addresses
No Load Balancing: Traffic doesn't get distributed across service endpoints
No Health Checking: Unhealthy pods still receive traffic
Manual Updates: Changes require configuration updates
This approach works for simple testing but isn't viable for production environments.
Internal Load Balancers + DNS
A step up from direct IP communication is exposing services via internal load balancers and using DNS for discovery:
How It Works:
Expose services in each cluster using Kubernetes Service type LoadBalancer with internal-only accessibility
Configure AWS Route 53 Private Hosted Zones shared across VPCs
Register the load balancer endpoints in Route 53
Services in one cluster connect to services in another cluster using DNS names
Advantages:
Uses Kubernetes native Service construct
Provides load balancing across pods
Abstracts away direct IP dependencies
Leverages DNS for service discovery
Limitations:
Requires additional AWS resources (NLBs/ALBs)
Manual DNS management or additional tooling like ExternalDNS
No automatic failover between clusters
Additional hop through the load balancer
Kubernetes MultiCluster Services API
The Kubernetes MultiCluster Services (MCS) API provides a more native approach to connecting services across clusters:
Conceptual Overview:
The MCS API extends Kubernetes' native service discovery and load balancing capabilities across cluster boundaries. It introduces two key resources:
ServiceExport: Marks a Service in one cluster to be exposed to other clusters
ServiceImport: Represents a service from another cluster

How It Works:
A service is created in Cluster A
The service is exported using ServiceExport in Cluster A
A ServiceImport is created in Cluster B
Pods in Cluster B can now discover and connect to the service in Cluster A using the imported service name
Key Components:
MultiCluster Service Controller: Manages ServiceExport and ServiceImport resources
DNS Controller: Configures DNS resolution for imported services
Endpoint Slices: Distributes endpoint information across clusters
Implementation Options:
Submariner: Implements the MCS API and handles both service discovery and network connectivity
Istio/Service Mesh: Many service meshes now support multi-cluster service discovery
Advantages:
Kubernetes-native approach
Automated service discovery
Support for standard Kubernetes features like health checks and load balancing
Abstracts away underlying network complexity
Current Status:
The MCS API is still evolving, with implementations varying in maturity. It's part of the Kubernetes SIG-Multicluster work, aiming to standardize cross-cluster service communication.
Submariner: Dedicated Cross-Cluster Connectivity
Submariner is a CNCF project specifically designed to enable direct networking between multiple Kubernetes clusters.
Conceptual Overview:
Submariner creates secure tunnels between clusters, establishing a flat network that allows pods in one cluster to directly communicate with pods and services in remote clusters. It's a comprehensive solution that handles both the networking layer and service discovery aspects.

How It Works:
Deploy Submariner operators in each cluster
Designate one cluster as the broker (central coordination point)
Join each cluster to the broker, establishing encrypted IPsec tunnels
Submariner handles IP address management, ensuring non-overlapping CIDRs
The Lighthouse component provides DNS-based service discovery
Key Components:
Gateway Nodes: Run the Submariner Gateway engine to establish secure tunnels
Broker: Coordinates the exchange of connection information
Route Agent: Manages routing rules on each node
Lighthouse: Provides DNS discovery for cross-cluster services
Service Discovery API: Implements the Kubernetes MultiCluster Services API
Advantages:
Full stack solution covering both networking and service discovery
Multiple connectivity options (including over the internet)
Support for service discovery via the MultiCluster Services API
TCP and UDP connectivity without requiring application changes
NAT traversal capabilities
Disadvantages:
Requires gateway nodes with public IP addresses for internet-based connectivity
More networking overhead compared to application-layer solutions
Skupper: Application Layer Virtual Network
Skupper takes a different approach by creating an application-level virtual network without requiring changes to the underlying network infrastructure.
Conceptual Overview:
Unlike Submariner, which operates at the network layer (L3), Skupper works at the application layer (L7). It creates secure application-level connections between services across clusters without requiring VPN tunnels, special firewall rules, or cluster admin privileges.
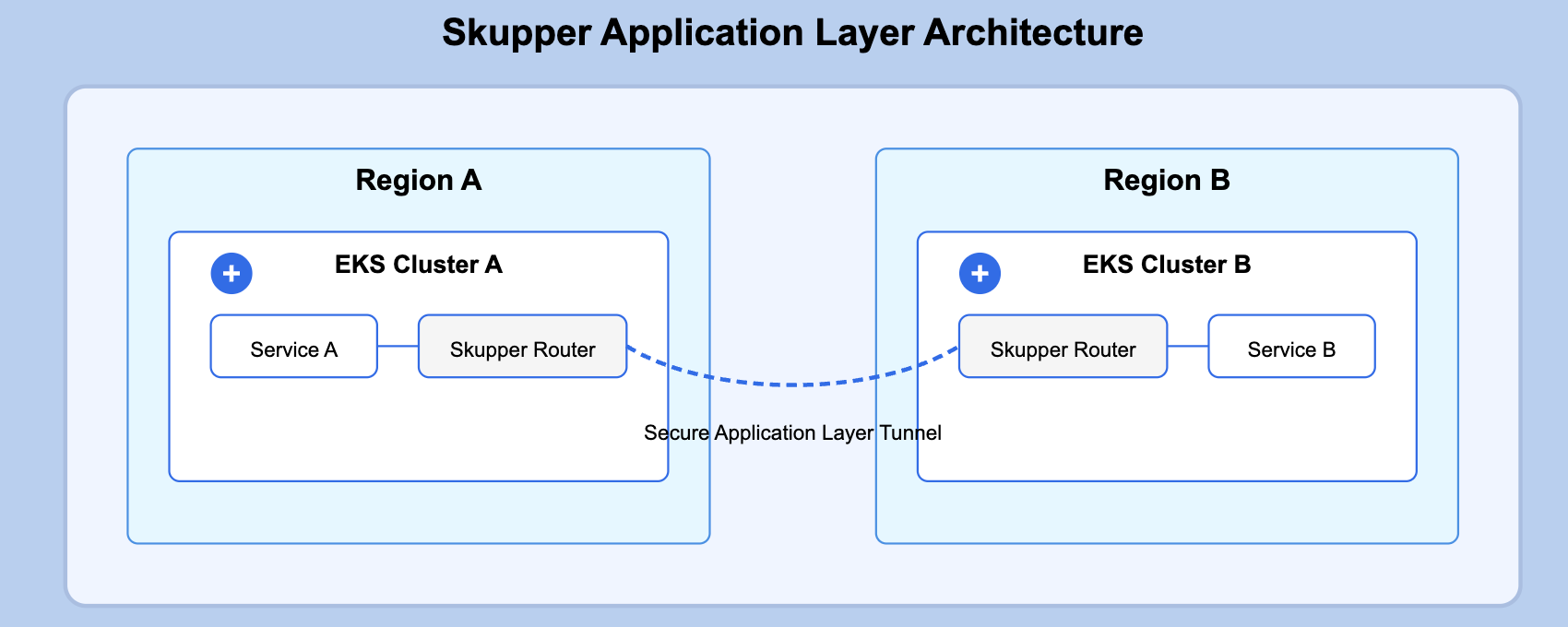
How It Works:
Deploy Skupper routers in each namespace that needs cross-cluster communication
Create token-based links between Skupper router instances
Expose services you want to be accessible from other clusters
Skupper handles routing requests to the appropriate destination
Key Components:
Skupper Router: Deployed as a pod in each namespace
Router Console: Web interface for visualizing connections
Service Interface: Allows services to be accessed across clusters
Token-based Links: Secure connections between router instances
Advantages:
Works without cluster admin privileges
No need to modify underlying network infrastructure
Operates through existing firewalls
Minimal networking knowledge required
Supports multi-cluster, multi-cloud, and hybrid cloud scenarios
Disadvantages:
Application layer only (no direct pod-to-pod L3 connectivity)
Higher latency compared to network-layer solutions
Less transparent to applications than L3 solutions
Cross-Cluster Service Mesh Approach
Service meshes provide an application-level networking layer that can span multiple clusters:
Conceptual Overview:
A service mesh creates an overlay network of proxies (sidecars) that handle service-to-service communication. When extended across clusters, it provides unified service discovery, traffic management, and security.
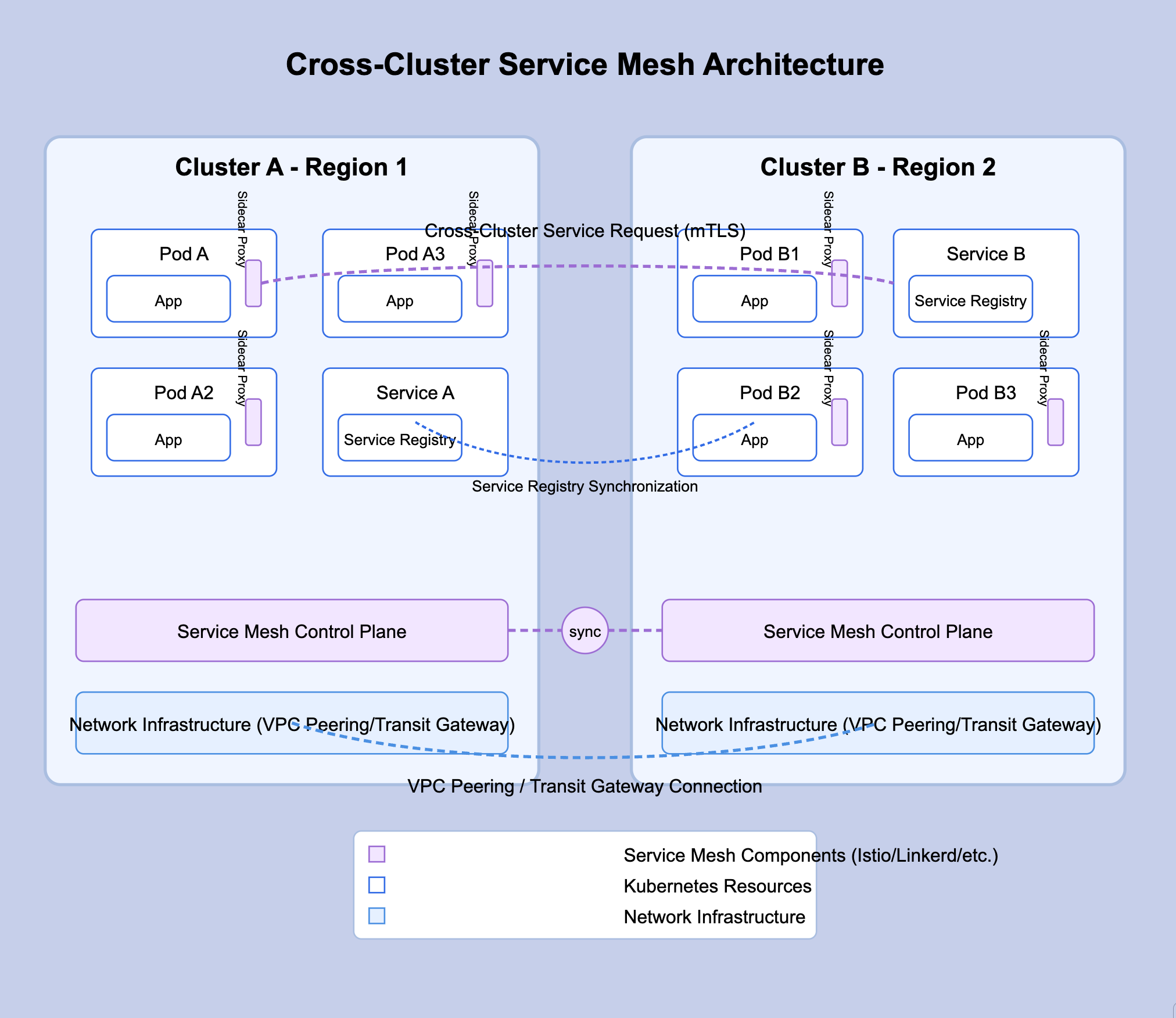
How It Works:
Deploy service mesh control plane with multi-cluster configuration
Install service mesh data plane (proxies) in each cluster
Configure the mesh to share service registries across clusters
Services discover and communicate with each other through the mesh
Popular Service Mesh Options:
Istio: Robust multi-cluster support with various deployment models
Linkerd: Lighter-weight option with multi-cluster capabilities
AWS App Mesh: AWS-native service mesh with cross-cluster support
Consul Connect: HashiCorp's service mesh with multi-datacenter support
Advantages:
Unified service discovery across clusters
Advanced traffic management capabilities
Consistent security policies (mTLS)
Rich observability
Works with or without direct network connectivity
Disadvantages:
Increased complexity
Performance overhead from proxies
Learning curve for operations teams
Putting It All Together: Reference Architectures
Let's explore how these components fit together in different scenarios:
Reference Architecture 1: Transit Gateway + MCS API
In this architecture, Transit Gateway provides the network foundation, while the MultiCluster Services API handles service discovery:

Network Layer:
Transit Gateways connect VPCs across regions
Security groups allow cluster-to-cluster communication
Route tables direct traffic between VPCs
Service Discovery Layer:
MCS API controllers run in each cluster
Services are exported from source clusters
Services are imported in destination clusters
CoreDNS is configured to resolve cross-cluster service names
Communication Flow:
Pod in Cluster A wants to reach service-b in Cluster B
Pod looks up service-b using Kubernetes DNS
DNS returns endpoints for service-b in Cluster B
Pod connects to service-b using private IP routing through Transit Gateway
Traffic reaches pods backing service-b in Cluster B
Reference Architecture 2: VPC Peering + Service Mesh
This architecture uses VPC Peering for network connectivity and a service mesh for service discovery and advanced traffic management:
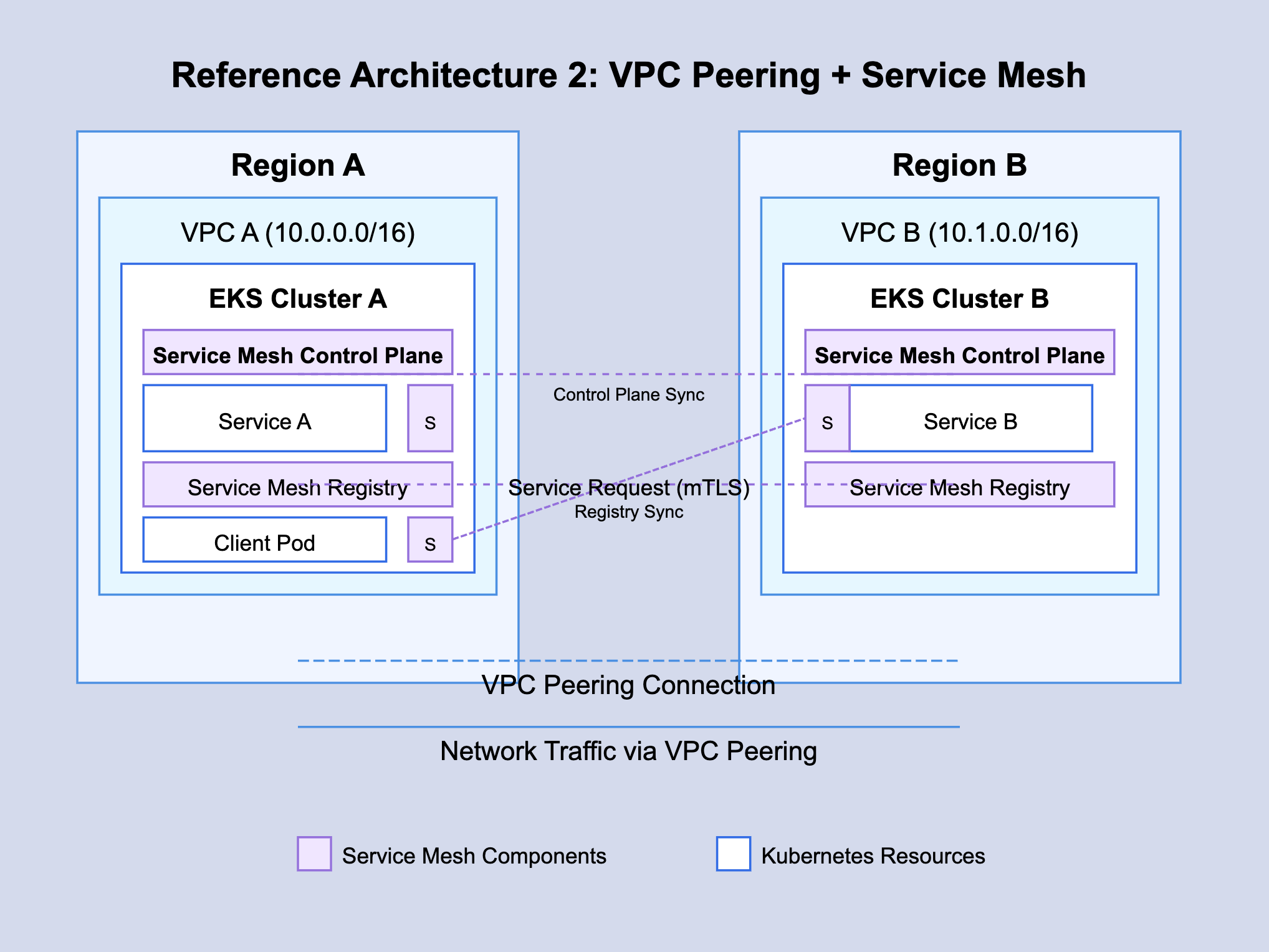
Network Layer:
VPC Peering connects cluster VPCs
Security groups allow mesh-to-mesh communication
Route tables direct traffic between VPCs
Service Mesh Layer:
Service mesh control plane spans clusters
Sidecars are injected alongside application pods
Mesh configuration defines multi-cluster service registry
Communication Flow:
Pod in Cluster A wants to reach service-b
Request goes to local sidecar proxy
Proxy consults mesh registry to locate service-b in Cluster B
Proxy routes request to service-b endpoints through VPC Peering
Remote proxy receives the request and forwards to local service-b pod
All communication is secured with mTLS
Implementation Considerations and Best Practices
Regardless of the approach you choose, consider these crucial aspects:
CIDR Planning
Careful IP address planning is essential for cross-cluster communication:
Ensure non-overlapping CIDR blocks for pod and service networks across clusters
Plan for future growth and additional clusters
Document IP allocation to prevent future conflicts
Consider using a tool like IPAM (IP Address Management) for larger deployments
Service Discovery and DNS Configuration
DNS is often the glue that makes cross-cluster communication work:
Configure CoreDNS for stub domains to forward queries for remote cluster services
Use consistent naming conventions for services across clusters
Consider global DNS solutions like Route 53 Private Hosted Zones
Implement DNS caching to reduce lookup latency
Security Considerations
Cross-cluster communication introduces new security challenges:
Implement mTLS for all pod-to-pod communication
Use network policies to restrict traffic flows within and between clusters
Follow least-privilege principles for IAM roles
Encrypt all cross-region traffic
Implement consistent security policies across clusters
Consider using service mesh authorization policies for fine-grained access control
Operational Readiness
Monitoring and troubleshooting cross-cluster setups require special attention:
Implement distributed tracing across clusters
Set up centralized logging for cross-cluster requests
Monitor cross-cluster network metrics
Create runbooks for troubleshooting connectivity issues
Regularly test failover scenarios
Solution Comparison
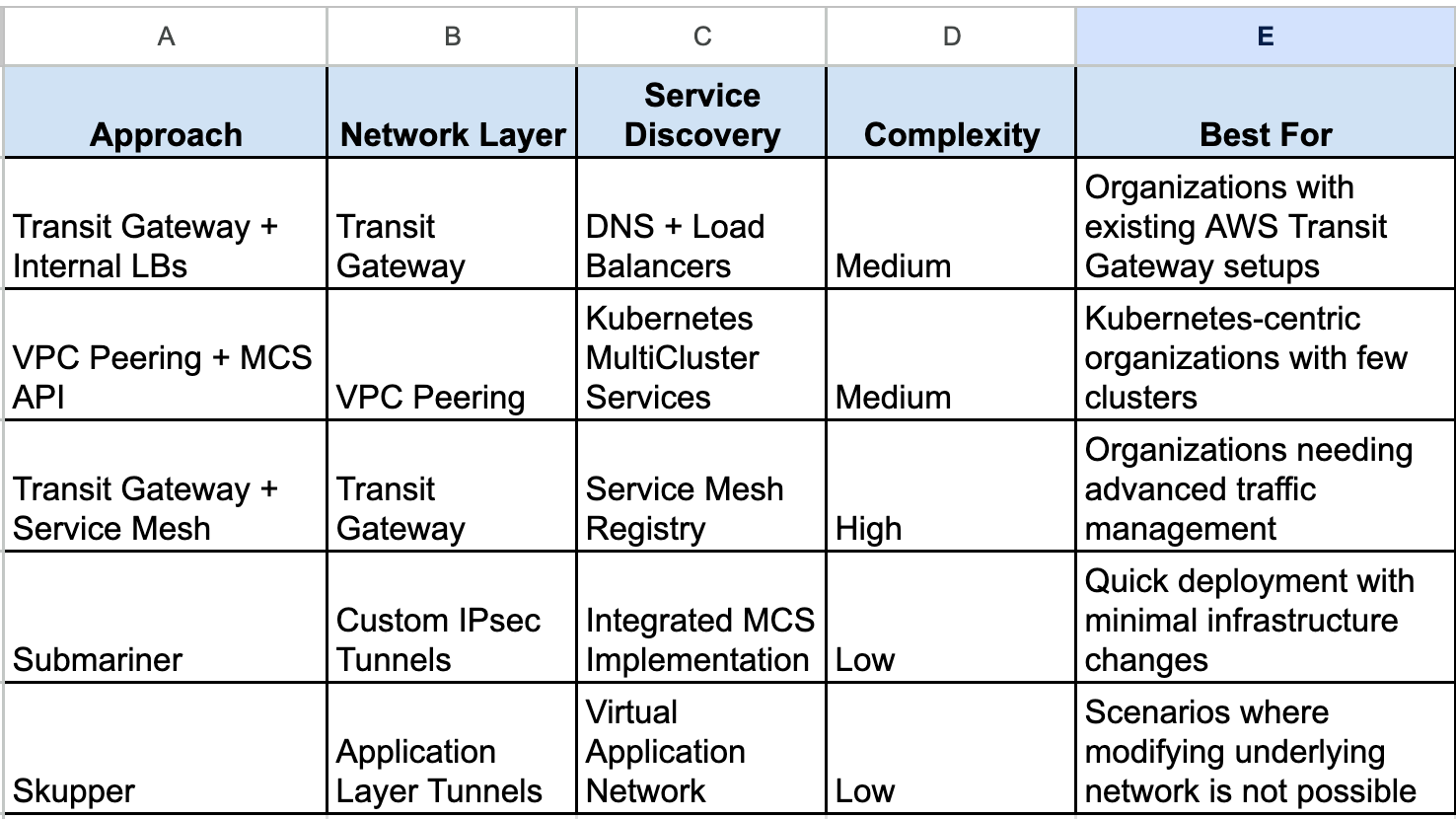
Conclusion
Connecting Kubernetes pods across regions and VPCs requires addressing both the infrastructure networking layer and the Kubernetes service discovery layer. The MultiCluster Services API represents a significant step toward standardizing cross-cluster communication in Kubernetes, though it's still evolving.
For most organizations, the journey to multi-cluster connectivity begins with establishing solid network infrastructure (via Transit Gateway or VPC Peering) and then layering on service discovery mechanisms that fit their operational model—whether that's using internal load balancers with DNS, implementing the MCS API, or deploying a service mesh.
As your Kubernetes footprint grows globally, investing in a well-designed cross-cluster communication strategy will pay dividends in resilience, performance, and operational simplicity.
References
About the Author: Gourav Shah is a cloud infrastructure and devops architect specializing in distributed Kubernetes deployments for global enterprises.